The Silicon Showdown: How GPUs and TPUs are Powering the AI Revolution at leading tech Firms
By Horay AI Team|
In the world of machine learning, hardware plays a pivotal role in efficiently training and deploying models. The rise of large-scale models like GPT-4 all require immense computing power, and this is where specialized hardware, namely GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units), comes into play. Both of these processors are designed to handle large-scale computations, which are critical to deep learning tasks. This article will dive to explore the roles of GPUs and TPUs, their significance in machine learning, and how leading tech firms like Google leverage them to fuel their computing power.
GPUs: The Engine Behind Modern AI
Originally designed for rendering graphics in video games, GPUs have found their sweet spot in parallel computing, which is at the heart of machine learning. A GPU consists of thousands of smaller cores that makes it able to process multiple tasks simultaneously. When training a model, GPUs accelerate the calculations required for tasks like matrix multiplication. Their parallel architecture allows them to process large chunks of data in parallel, making them ideal for complex, data-heavy tasks like deep learning.
NVIDIA, a leading GPU manufacturer, has been at the forefront of developing GPUs tailored specifically for machine learning. Their H100 Tensore Core GPU is especially designed to meet the needs of AI researchers and companies developing LLMs. These GPUs are often used in data centers and cloud computing environments to provide the necessary computing power for training advanced models.
TPUs: Google’s Specialized Hardware for AI
While GPUs have become a mainstay in AI, Google consequently introduced the Tensor Processing Unit (TPU) in 2016 as a custom solution for deep learning tasks. TPUs are application-specific integrated circuits (ASICs) designed to handle tensor operations, which are foundational in neural networks. Unlike general-purpose GPUs, TPUs are specifically optimized for machine learning workloads, making them more efficient for certain tasks, especially in large-scale deployments.
Google’s TPUs are primarily used in its data centers to power various machine learning applications, from search algorithms to Google Translate. TPUs always excel in tasks that require high-throughput processing, such as training LLMs or running inference on models with billions of parameters.
Comparison between GPUs and TPUs
This video introduces the development history of various processors and how each of them works. Apart from the CPUs, which are commonly know as the brain of the computer, GPUs have far more cores than CPUs, in order to handle integer computation per cycle and train deep learning models that perform amount of matrix multiplication on large datasets. Additionally, TPUs contain thousands of multiple accumulators that allow the hardware to perform matrix multiplication without the need to access the registers or shared memory like GPUs would.
Both GPUs and TPUs have their strengths in machine learning, but they serve slightly different purposes. GPUs are more versatile and can handle a broader range of tasks, including non-AI workloads, while TPUs are highly specialized for AI tasks. For organizations that rely heavily on machine learning, TPUs always offer efficiency and performance benefits in terms of both speed and power consumption.
The Hardware Arms Race Among Tech Giants
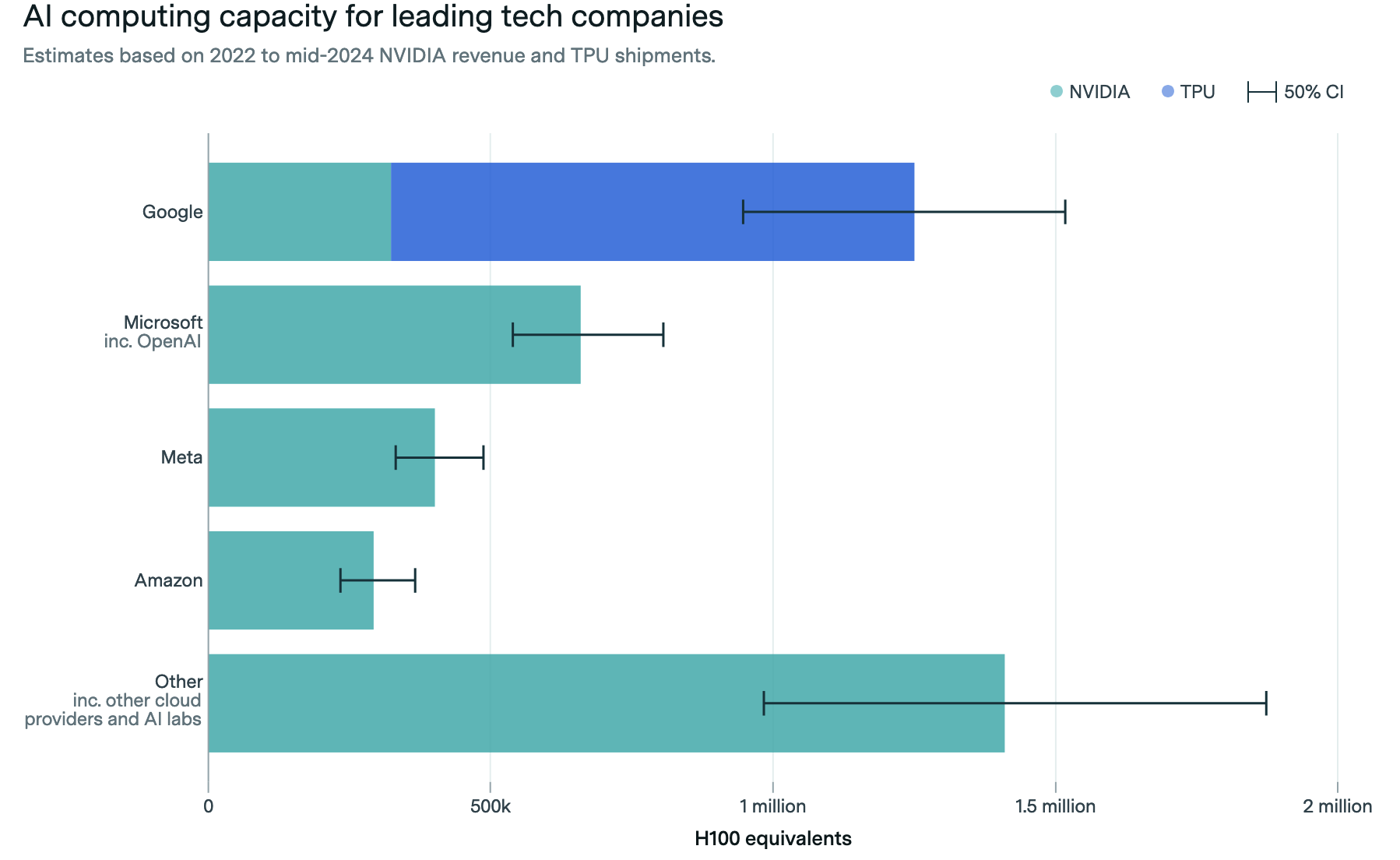
The growing demand for machine learning models has led to an arms race among tech companies to secure more powerful hardware. According to the Epoch AI report, Google is the leader in computing power thanks to its investment in TPUs. Google’s TPU fleet is estimated to be around 930,000 H100-equivalent units, dwarfing the GPU fleets of other companies. Google also utilizes 320,000 GPUs, likely for tasks outside of their TPU-optimized systems.
Microsoft with OpenAI come in as the closest challengers, with a significant portion of their computing power being GPU-based. Their investment in OpenAI and its partnership with NVIDIA has then allowed them to amass a formidable GPU fleet.
Meta, the parent company of Facebook, is also heavily invested in AI infrastructure, with an estimated 400,000 GPUs. Meta’s investment is tied to its AI ambitions, particularly in deploying models for content moderation, recommendation systems, and virtual/augmented reality applications within the metaverse.
Amazon, the leader in cloud computing through AWS (Amazon Web Services), has a relatively smaller GPU fleet compared to above firms. However, AWS’s dominance in the cloud market allows them to provide scalable machine learning services to customers around the globe.
The 'Other' Players in the AI Hardware Ecosystem
Interestingly, the Epoch AI report also highlights a significant chunk of computing power attributed to 'Other' companies. This category includes players like Tesla, Bytedance, and CoreWeave, which collectively possess around 1.4 million H100-equivalent units. These companies, while not traditionally associated with AI research at the scale of Google or Microsoft, have ramped up their investments in machine learning hardware to support various initiatives. Tesla, for instance, relies on vast amounts of computational power for training its autonomous driving systems, while Bytedance also uses machine learning extensively for TikTok’s recommendation algorithms.
How Hardware Investments Shape AI Capabilities
The scale of hardware investments by these tech companies is directly affecting their ability to innovate in AI models. More GPUs and TPUs always translate into faster training times, the ability to run larger models, and greater capacity for experimentation. As companies like Google, Microsoft, and Meta compete to develop state-of-the-art models, their access to cutting-edge hardware becomes a critical differentiator.
For instance, Google’s lead in TPU deployment crucially gives it a strategic advantage in training massive models like PaLM. Similarly, Microsoft’s partnership with OpenAI and its heavy investment in NVIDIA GPUs allow it to stay competitive in the race for the most powerful language models.
At the same time, these hardware investments reflect a broader trend of companies moving toward vertical integration in AI development. By owning both the hardware and the software stack, tech companies will then be able to optimize their models to run more efficiently, reduce costs, and push the boundaries of what’s possible with AI.
Conclusion
Generally, the machine learning landscape is countinuosly shaped by the computing power that companies can muster, and the ongoing arms race for GPUs and TPUs is a testament to the growing importance of hardware in AI. With Google leading the charge in TPU development and Microsoft building out their GPU fleets, the future of AI will be defined by those who can harness the most computational power to a large extent. As these companies continue to scale their hardware investments, we can expect even more breakthroughs in AI in the coming years.
Please stay tuned to see what exciting changes these AIs can bring to humanity in the near future!