Qwen2.5-Coder-32B-Instruct: A Groundbreaking Advancement in Open-Source Coding
By Horay AI Team|
Since Qwen2.5 (Find out more: Qwen2.5: Alibaba's Latest Open-Source Series of Large Models) was published by Qwen Team the at Alibaba on September 19, 2024, it has become a standing out series of large language models and multimodal models. This series is composed by the open-source LLM Qwen2.5, as well as specialized models for programming, Qwen2.5-Coder, and for mathematics, Qwen2.5-Math.
Just on 12 November, Qwen Team officially open-sourced the code-specific model Qwen2.5-Coder Series, and described it as "Powerful", "Diverse" and "Practical". For "Powerful", Qwen2.5-Coder-32B-Instruct now holds the title as the state-of-the-art open-source code model, offering coding skills comparable to GPT-4-turbo. It not only excels in coding but also displays strong general and mathematical abilities. "Diverse" then refers to a number of different model sizes to meet varied developer demands, where there are 4 additional sizes—0.5B, 3B, 14B, and 32B instead of simply previous 1.5B and 7B models. Qwen2.5-Coder is also able to handle across applications, including code assistance and artifact generation, showcasing its utility in real-world "Practical"s.
As always, Horay AI is the first to go live with Qwen2.5-Coder-32B-Instruct, the accelerated version of reasoning, which eliminates the deployment threshold for developers, and brings a more efficient user experience by simply calling the API easily.
Key Highlights of Qwen2.5-Coder-32B-Instruct
1. Comprehensive Benchmark Performance
Qwen2.5-Coder-32B-Instruct excels as a state-of-the-art model, leading in key benchmarks with top scores like HumanEval of 92.7, and EvalPlus with 86.3, showcasing its high coding accuracy and strong performance that outperformed the GPT-4o in all of these indicators. Qwen2.5-Coder-32B-Instruct performs excellently across more than 40 programming languages, scoring 65.9 on McEval, with impressive performances in languages like Haskell and Racket. It also achieves impressive and consistent scores well across other benchmarks, reflecting its versatility and adaptability across diverse coding tasks.
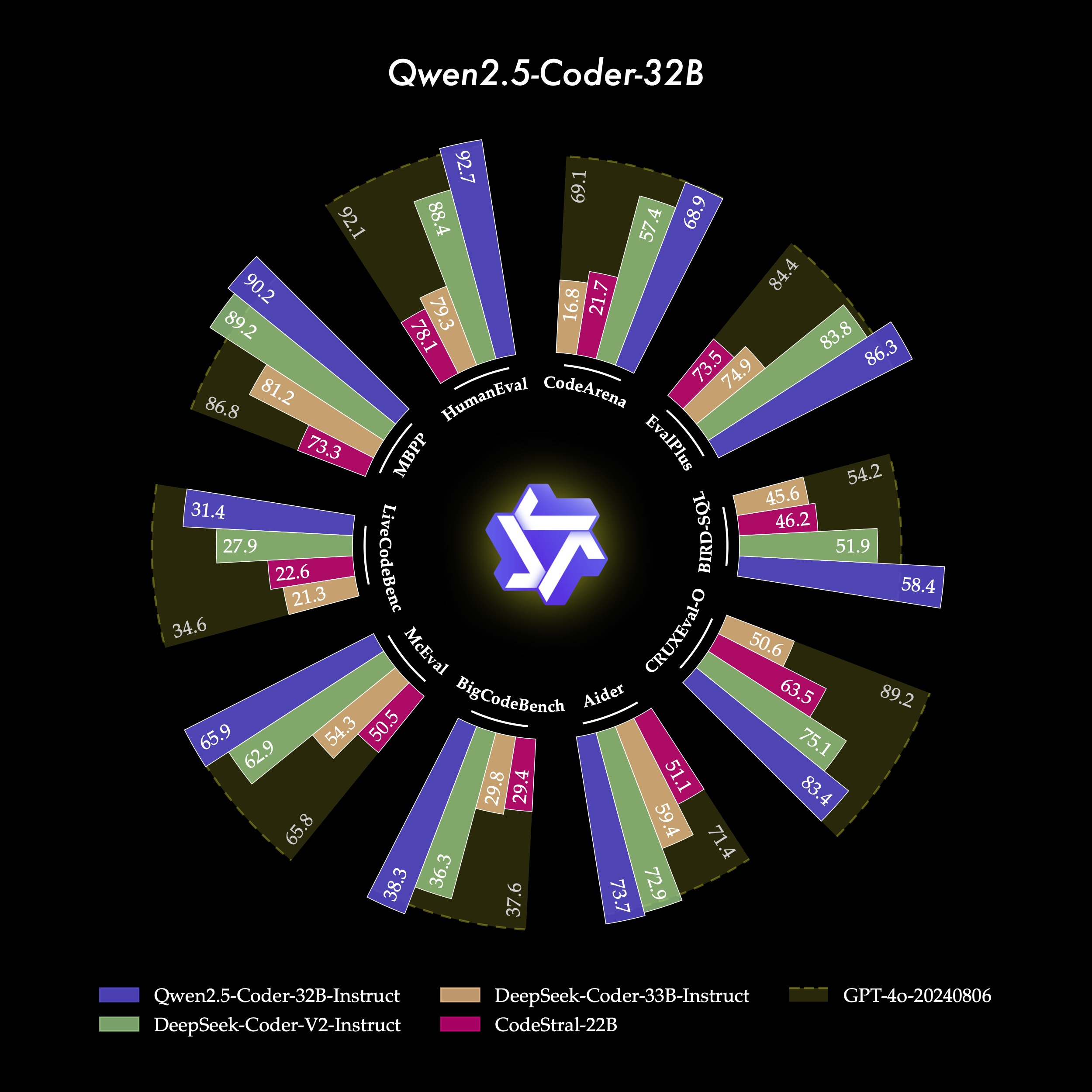
2. Strong Coding capabilities
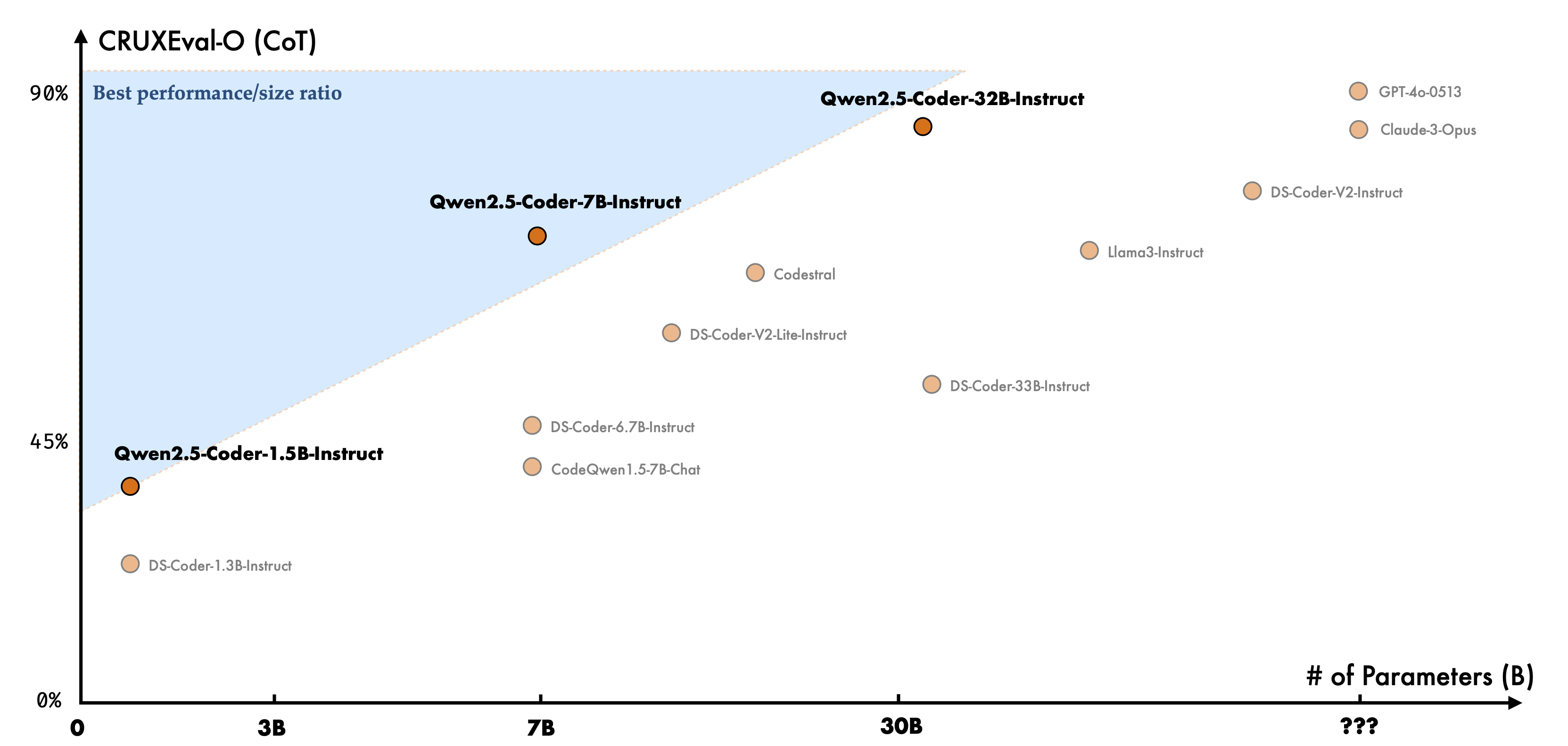
Qwen2.5-Coder-32B-Instruct achieves SOTA-level performance among open-source models. It excels in Code Repair, a crucial programming skill that enables users to quickly identify and fix errors, streamlining the coding process. In the Aider benchmark, a popular test for code repair, the model scored 73.7, performing even better than the GPT-4-turbo. Additionally, in Code Reasoning, which involves understanding code execution and accurately predicting inputs and outputs, Qwen2.5-Coder-32B-Instruct has further enhanced its reasoning abilities.
Qwen2.5-Coder-32B-Instruct, the largest in this series in the image below, demonstrates exceptional performance, achieving one of the highest scores in the benchmark while falling a little beyond the optimal performance-to-size area. Qwen2.5-Coder-7B-Instruct and Qwen2.5-Coder-1.5B-Instruct also perform well, demonstrating efficient use of parameters compared to other models with similar sizes.
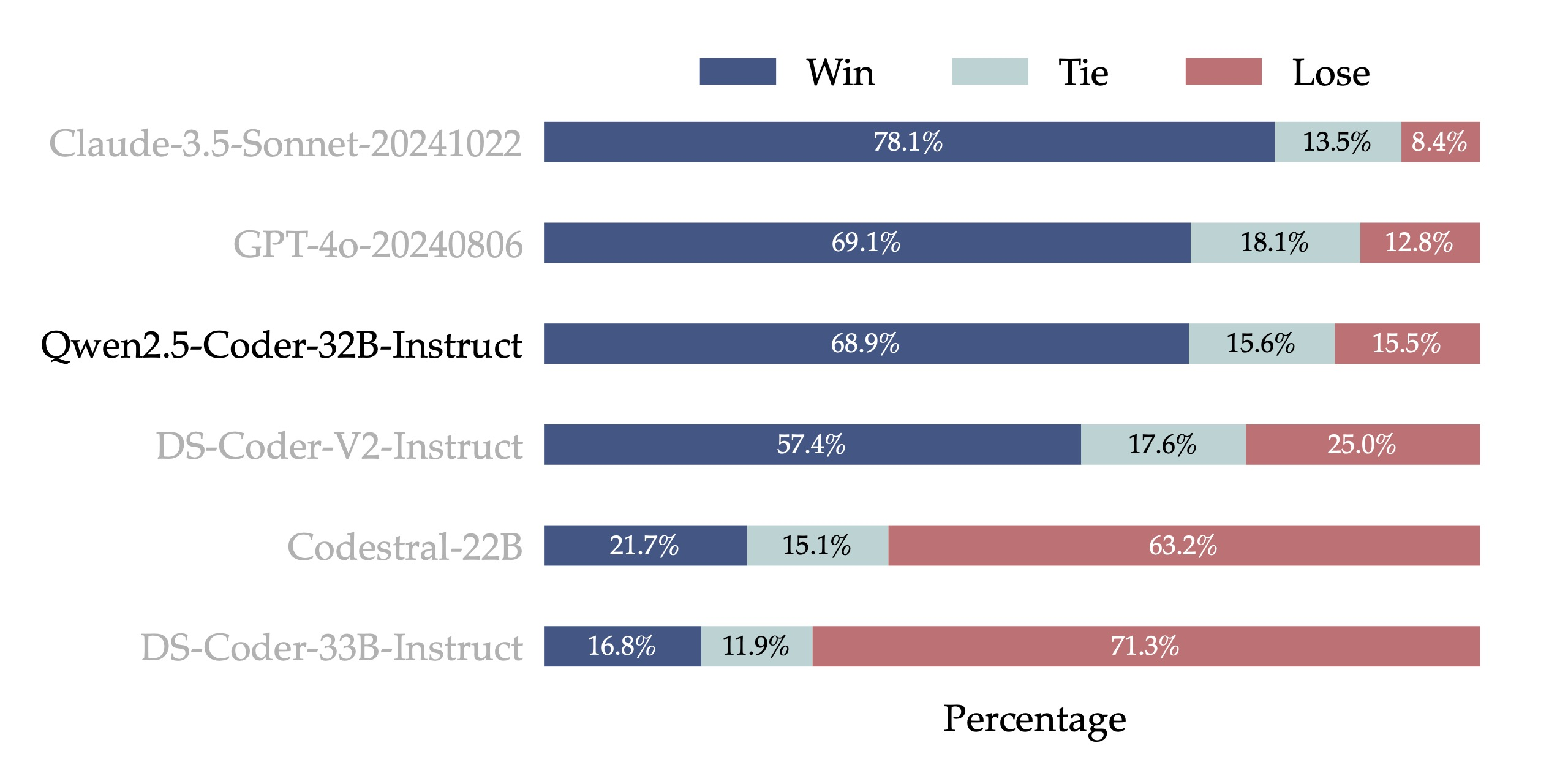
3. Human Preference Alignment
An internal evaluation benchmark, Code Arena (similar to Arena Hard) has been created to evaluate how well Qwen2.5-Coder-32B-Instruct could do to align with human preferences. The evaluation employed GPT-4o as the benchmark model, applying an 'A vs. B win' method, which calculates the percentage of test cases where one model outperforms the other.
In the results, Qwen2.5-Coder-32B-Instruct demonstrates strong preference alignment, achieving a 68.9% win rate, which closely matches the 69.1% score of GPT-4o. It outperforms DS-Coder-V2-Instruct, and shows a significant advantage over Codetral-22B and DS-Coder-33B-Instruct. This performance greatly highlights Qwen2.5-Coder-32B-Instruct’s capability in aligning with human coding preferences effectively. This is a significant achievement, as it demonstrates the model’s ability to align with human preferences and perform well in tasks that require reasoning.
4. Multilingual Versatility
With robust compatibility across more than 40 programming languages, Qwen2.5-Coder-32B-Instruct stands out as an exceptional tool for developers working in multilingual environments. This wide-ranging language support makes it highly versatile for various real-world applications, allowing developers to seamlessly switch between languages and adapt to different coding scenarios without limitations. Whether it's for web development, data science, software engineering, or specialized applications, Qwen2.5-Coder-32B-Instruct provides a comprehensive, powerful solution that meets the needs of today’s global, cross-language development landscape.
Applications - Assessing the Capabilities of Qwen2.5-Coder-32B-Instruct
In the "Qwen-2.5 Coder 32B: BEST Opensource Coding LLM EVER!" video, the Youtuber discusses testing the Qwen2.5-Coder-32B-Instruct model by providing it with a variety of prompts to assess its capabilities in tasks such as writing Python functions, creating a weather dashboard, generating SVG code for a butterfly shape, and implementing a graph algorithm. The results showcase a mix of successes and challenges for the model.
The model demonstrates its strengths in tasks like coding functions and creating the weather dashboard, showcasing its ability to handle programming-related tasks. However, when it comes to generating accurate SVG code, the model struggles, highlighting the limitations in its understanding of complex data structures and mathematical representations. Despite the occasional shortcomings, the model still shows potential in creating recognizable patterns, suggesting that its capabilities may depend on the user's own knowledge of basic programming skills and data structures. The Youtuber also explores the model's implementation of the Dijkstra algorithm in Python, which successfully showcases the path from point A to point D. Nonetheless, the model's attempt to generate Conway's Game of Life, a cellular automaton, falls short, despite efforts to run it in VS Code, leading to a failed test.
Despite this setback, the Youtuber praises the Qwen2.5-Coder-32B-Instruct as a strong open-source coding model with 32 billion parameters, outperforming GPT-4o and competing with Claude 3.5 Sonnet in coding capabilities, making it one of the best open-source models available for coding tasks.
Where to Access?
- Horay AI: https://www.horay.ai/models
- Hugging Face: https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct
- Github: https://github.com/QwenLM/Qwen2.5-Coder
Conclusion
Qwen2.5-Coder-32B-Instruct developed by Alibaba's Qwen Team represents a watershed moment in the world of open-source coding tools. This state-of-the-art LLM has not only set new benchmarks in coding accuracy and performance, but it has also showcased an unprecedented level of versatility and human preference alignment. Through the detailed evaluation, the model's exceptional capabilities across a diverse range of coding tasks can be witnessed – from writing Python functions and creating weather dashboards to implementing complex graph algorithms. While the model did face some challenges, its overall prowess in navigating the intricacies of programming languages, data structures, and algorithmic thinking is nothing short of remarkable.
Through our ongoing efforts to accelerate the Qwen2.5-Coder series into their suite of offerings, it is possible to empower developers worldwide, unlocking new levels of efficiency, creativity, and innovation in software development. By staying informed and engaged with our updates and advancements in this domain, all users could experience this transformative shift effectively, shaping the future of coding as we know it.