Qwen 2.5-Turbo Unleashed: Processing 10 full novels in One Go - The New Era of Long-Context AI
By Horay AI Team|
Introduction
In an era where efficiency and adaptability drive AI advancements, Alibaba has further unveiled its latest innovation recently: Qwen2.5-Turbo. Building on the foundation of its predecessor, Qwen2.5 (Prefer Reading or Watching to learn more), this model redefines the limits of context length, inference speed, and cost efficiency, catering to users with demanding long-text in particular and multitasking needs. Let’s delve into its transformative features and the underlying technology that powers this leap forward.
Key Highlights for Qwen2.5-Turbo
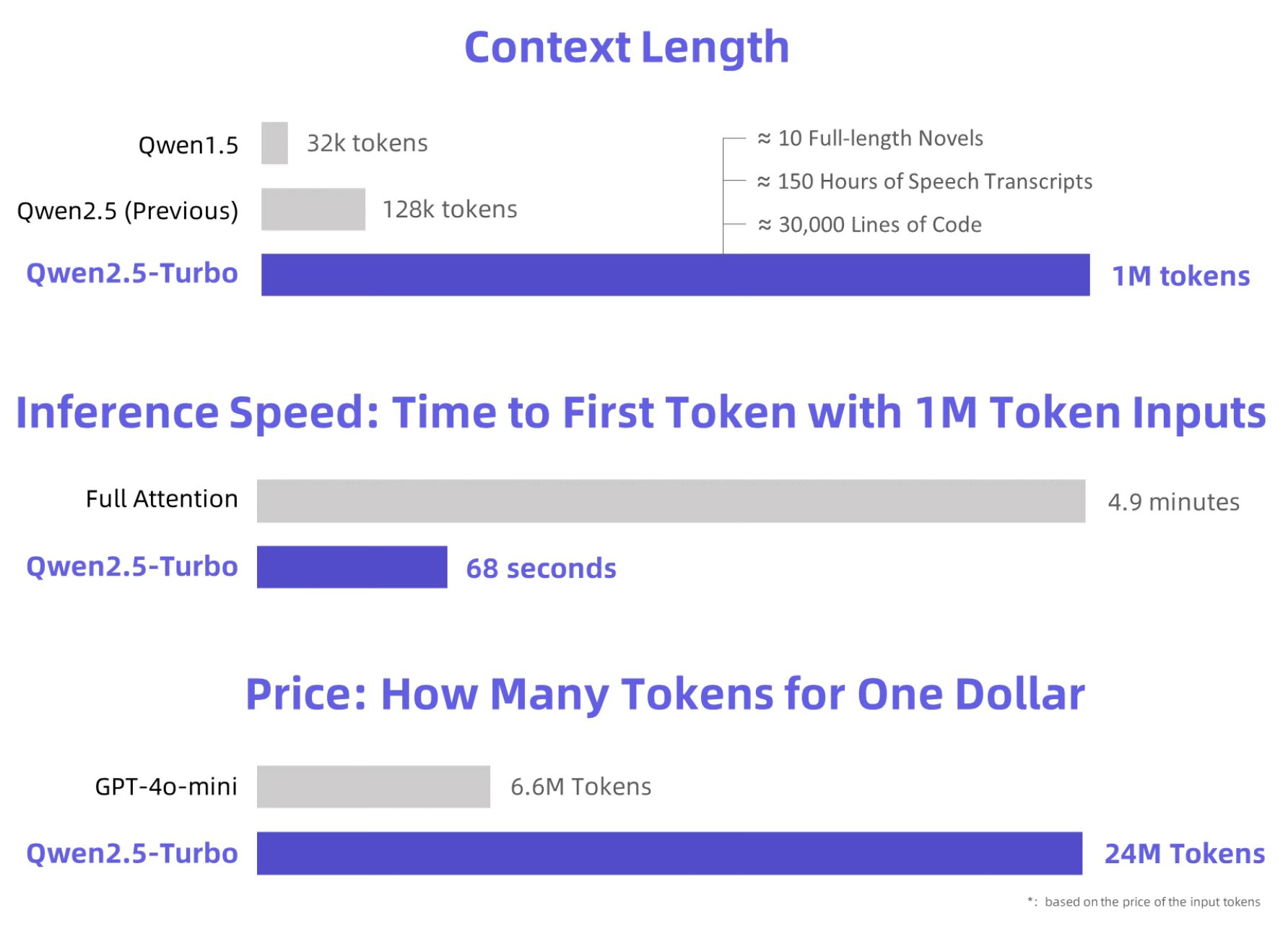
Extended Context Handling: 1M Tokens Unlocked
The hallmark of Qwen2.5-Turbo is its remarkable ability to process up to 1 million tokens, where got a dramatic increase from Qwen2.5’s 128k token capacity. To put this into perspective, the model can seamlessly handle the equivalent of 10 full-length novels, 150 hours of speech transcripts, or 30,000 lines of code.
Such an expansion is invaluable for applications requiring extensive text analysis or generation. Be it academic research, legal document review, or long-form storytelling, Qwen2.5-Turbo could ensure no detail is overlooked.
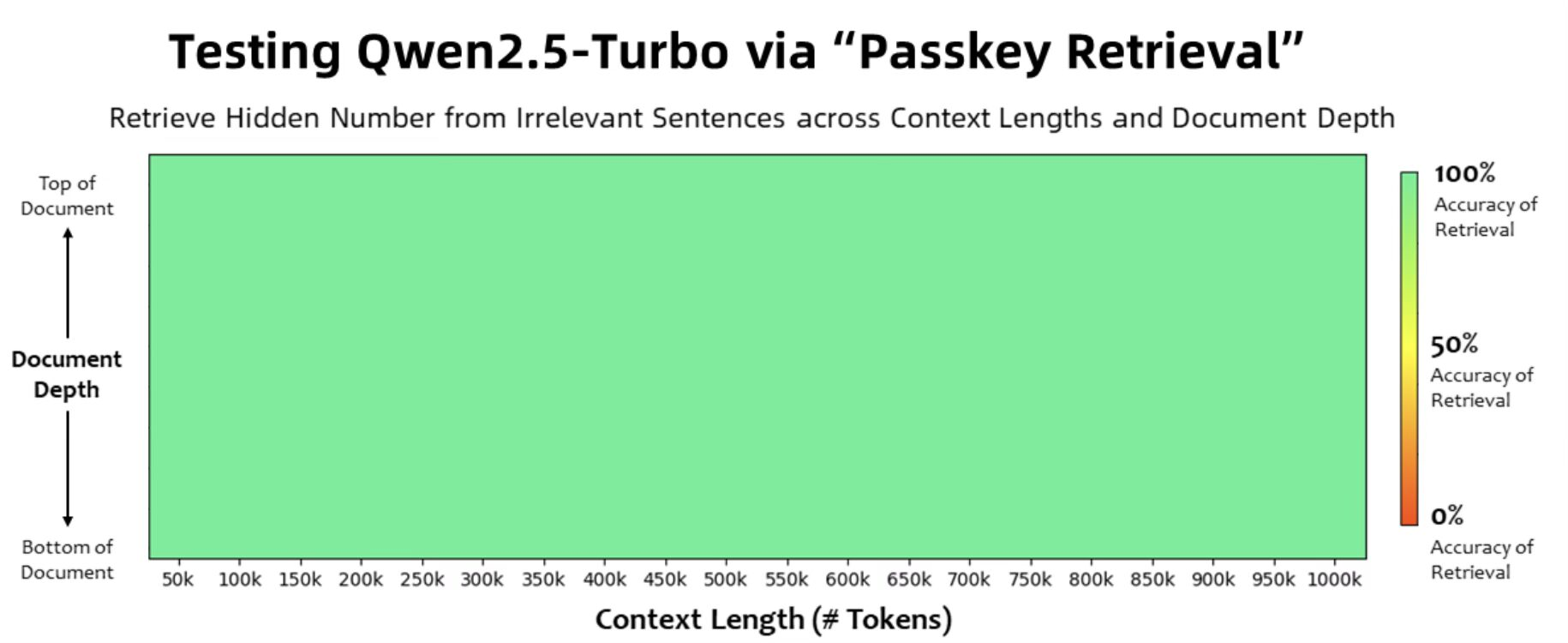
Moreover, it achieves 100% accuracy in the Passkey Retrieval task, demonstrating unmatched proficiency in locating specific information within ultra-long contexts. Benchmark results like 93.1 on the RULER evaluation further highlight its dominance over competitors such as GPT-4 and GLM4-9B-1M.
Faster and More Efficient Inference
Long-text models often struggle with speed, but Qwen2.5-Turbo breaks this stereotype easily. By leveraging sparse attention mechanisms, the model compresses computations significantly. The time to first token (TTFT) for 1M-token sequences has been slashed from 4.9 minutes to a mere 68 seconds, achieving up to a 4.3x speedup compared to earlier methods.
This improvement not only boosts productivity but also ensures scalability for real-time applications. Whether integrated into large-scale operations or embedded in individual projects, its speed can make sure smooth performance without compromising accuracy.
Affordable Excellence
Despite its cutting-edge capabilities, Qwen2.5-Turbo remains cost-effective. At only ¥0.3 per 1M tokens, it processes 3.6 times more tokens than GPT-4o-mini for the same price. This has made it an incredible practical choice for businesses and researchers looking to balance budget constraints with high computational needs.
Technological Foundations: What Makes It Tick
Qwen2.5-Turbo’s capabilities are underpinned by advanced architectures and techniques, including:
- Transformer Framework: Built on a robust Transformer model, Qwen2.5-Turbo excels in handling sequential data, such as text, by maintaining context and coherence over extensive ranges.
- Self-Attention and Sparse Attention Mechanisms: While self-attention captures relationships across inputs, sparse attention minimizes computational overhead for longer sequences, ensuring efficiency without losing detail.
- Pretraining and Fine-tuning: Pretrained on large-scale datasets, the model has acquired deep linguistic understanding. Task-specific fine-tuning further enhances its precision in niche applications.
Unparalleled Mastery of Long Contexts
Qwen 2.5-Turbo isn't just a AI model – it's a powerhouse when it comes to handling lengthy conversations and complex documents. Imagine being able to analyze entire research papers, technical documentation, or lengthy legal contracts without losing context or accuracy. This extended context window isn't just about quantity – it's about quality too. Qwen 2.5-Turbo maintains and even goes further in remarkable coherence and consistency throughout long interactions, understanding references and details from earlier in the conversation with impressive precision. Whether you're conducting in-depth document analysis, or maintaining complex, multi-topic discussions, the model's ability to maintain context transforms what could be fragmented interactions into smooth, contextually aware conversations. For businesses dealing with comprehensive documentation or developers working with large codebases, this extended context capability isn't just a feature – it's a game-changing advantage that sets Qwen 2.5-Turbo apart in the AI landscape.
Applications for Qwen2.5-Turbo
Long Text Analysis and Understanding
- Academic Papers and Research: Researchers often need to analyze multiple studies or lengthy datasets. Qwen2.5-Turbo can summarize findings, cross-reference key points, and extract specific details across millions of tokens, saving countless hours.
- Legal Documents: For lawyers or paralegals, combing through contracts, legal opinions, and case laws becomes efficient with Qwen2.5-Turbo. Its ability to locate relevant clauses or summarize voluminous case materials ensures accuracy and speed.
Creative Content Generation
- Writing Novels or Scripts: Authors can use the model to brainstorm ideas, develop plotlines, or even draft extensive segments of text. Its long-context capabilities ensure it remembers character arcs and thematic elements across chapters.
- News Reporting: Journalists covering complex stories can use Qwen2.5-Turbo to compile reports, analyze sources, and draft articles that blend clarity with in-depth coverage.
Education and Research
- Learning Aids: The model simplifies intricate topics, offering tailored explanations based on a learner’s proficiency level. This is particularly beneficial for STEM subjects, where understanding complex theories and equations is critical.
- Literature Reviews: Researchers benefit from the model’s ability to sift through academic papers, identify key insights, and synthesize findings into a coherent narrative.
Multilingual Applications
- Translation and Localization: The model is able to translate lengthy texts while preserving context and cultural nuances, making it ideal for global businesses.
Get Started with Qwen2.5-Turbo
- API access: users can easily embed various capabilities of Qwen2.5-Turbo into applications ranging from customer service bots to data analysis pipelines.
- Demo on Hugging FaceResearchers benefit from the model’s ability to sift through academic papers, identify key insights, and synthesize findings into a coherent narrative.
Conclusion
Qwen2.5-Turbo represents a quantum leap in language model technology. With its unparalleled context handling, swift processing, and affordability, it bridges the gap between cutting-edge research and real-world applications. Whether you're a content creator, a developer, or a researcher, this model equips you with the tools to tackle complex linguistic challenges effortlessly.
While Qwen2.5-Turbo has set a new standard, there’s always room for improvement. As Alibaba's AI Team prioritized, areas like real-world stability in long-sequence tasks and further reduction in inference costs can be further discovered . Future iterations promise to refine human preference alignment and optimize even larger-scale models, signaling a bright horizon for the Qwen series.
As Alibaba continues to push the boundaries of AI, Qwen2.5-Turbo stands as a testament to innovation’s power to transform how we interact with technology.