Mistral AI: Revolutionizing Multimodal AI with Pixtral Large
By Horay AI Team|
Introduction
Emerging from the vibrant French tech ecosystem in April 2023, Mistral AI has swiftly carved out a significant niche in the artificial intelligence landscape. The company's groundbreaking achievement is Pixtral Large, an innovative multimodal AI model that pushes the boundaries of visual and textual understanding. Pictral Large has been open sourced to the public and is currently being used by Mistral.AI's own chat assistant Le Chat.
Pixtral Large: A Technological Marvel
Core Specifications
Pixtral Large, the second model in Mistral’s multimodal series, introduces an impressive 128,000-token context window. This capability allows it to process up to 30 high-resolution images in a single input or handle the equivalent of a 300-page book, rivaling the performance of advanced models like those in OpenAI’s GPT series. Built on the foundation of Mixtral Large 2, a text-only model, Pixtral Large expands into multimodal tasks while maintaining exceptional text-generation quality. With a sophisticated architecture consisting of a 123-billion-parameter multimodal decoder and a 1-billion-parameter vision encoder, it excels in analyzing and integrating both text and visual data. This cutting-edge model represents a major milestone in AI, leveraging vast computational power and refined algorithms to achieve unparalleled accuracy in interpreting visual information. However, its deployment still requires significant resources, including over 200GB of memory and a high-performance GPU system.
Architectural Innovation
Vision encoder
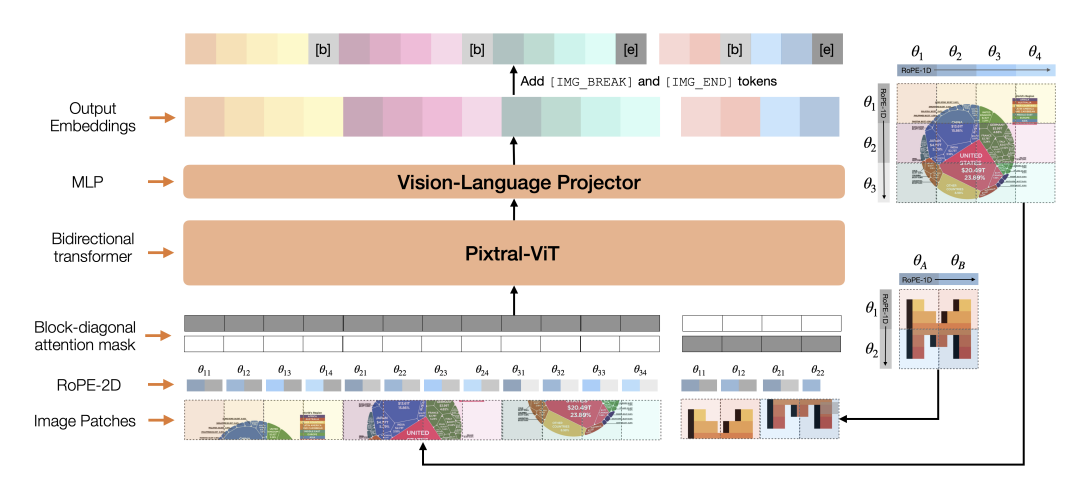
Mistral AI's Pixtral Large model features a custom-developed vision encoder called PixtralViT, designed to process images across a wide range of resolutions and aspect ratios. This encoder incorporates several key innovations which contribute to PixtralViT's ability to interpret visual data, contributing to the overall capabilities of Mistral AI's Pixtral Large multimodal model:
- Break Tokens: To help the model distinguish between images with the same number of patches but different aspect ratios, PixtralViT includes [IMAGE BREAK] tokens between image rows and an [IMAGE END] token at the end of the image sequence.
- Block-Diagonal Attention Masks: This technique successfully enables efficient processing of multiple images by isolating the attention computations for each individual image.
- ROPE-2D Encoding: PixtralViT replaces traditional learned and absolute position embeddings for image patches with relative, rotary position encodings. This improves the spatial representation of image patches, making the encoder adaptable to variable image resolutions and sizes.
Complete Pixtral Architecture
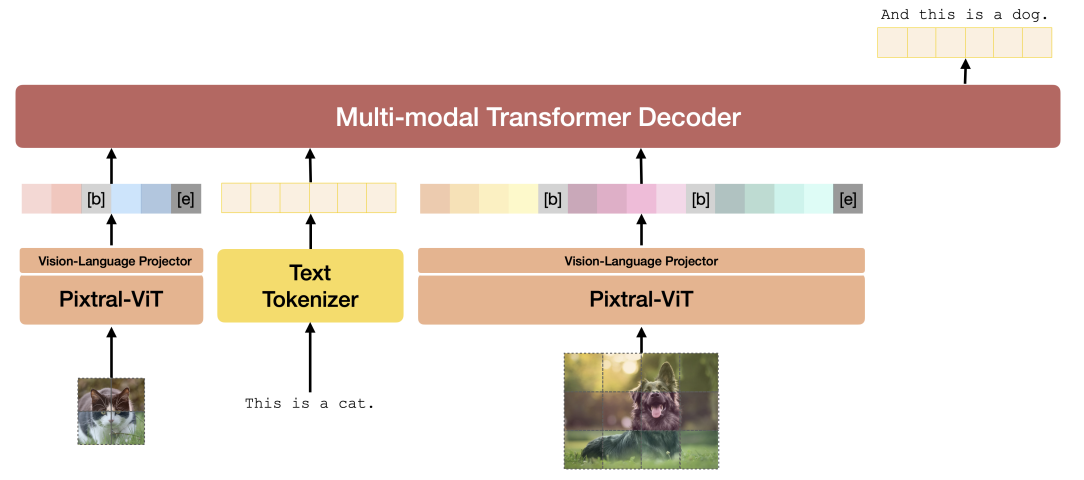
The Pixtral vision encoder is connected to the multimodal decoder through a two-layer fully connected network, where the multimodal decoder can predict the next text token given a sequence of text and images.. This network transforms the vision encoder's output to match the decoder's input embedding size, using a GeLU activation in the intermediate hidden layer. Pixtral can thus handle an arbitrary number of images as input, as long as they fit within its 128K context window. The multimodal decoder treats image tokens the same as text tokens, including applying RoPE-1D positional encodings. Notably, the decoder employs a causal self-attention mechanism, enabling capabilities like multi-image conversations.
The integration of the advanced PixtralViT vision encoder with the model's powerful language processing decoder greatly allows Pixtral Large to excel at tasks involving both textual and visual understanding.
Benchmark Excellence
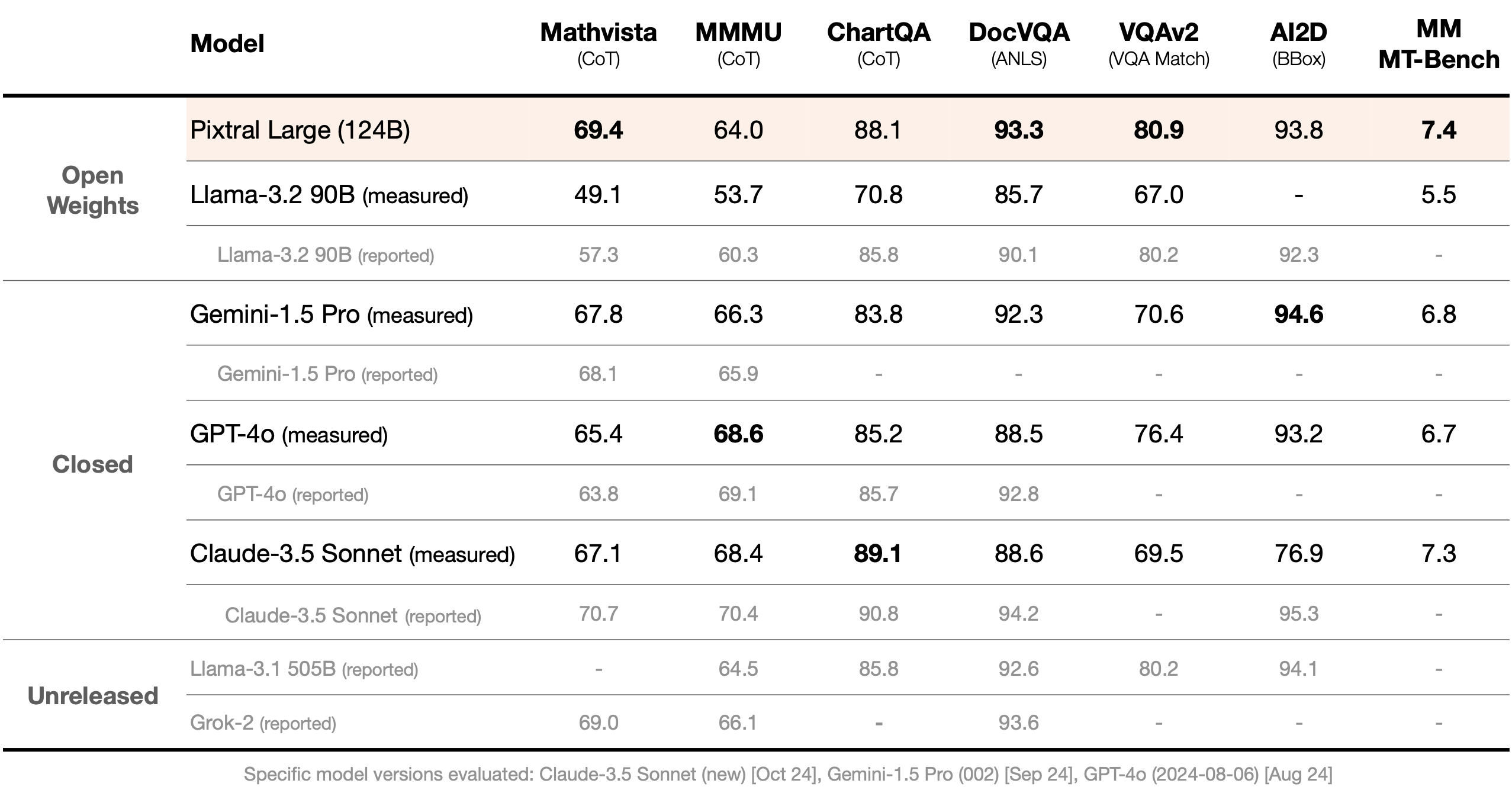
As can be seen from above table, Pixtral Large demonstrates exceptional performance across multiple multimodal benchmarks, leading the field in MathVista, DocVQA, and VQAv2 categories. Notably, it achieves top scores such as 69.4 on MathVista, outperforming its competitors in these specific tasks. Additionally, the model excels with an outstanding 93.8 score in AI2D, further reinforcing its dominance in multimodal capabilities.
While primarily a multimodal model, Pixtral Large also maintains competitive performance in text-only benchmarks. It achieves high rankings on metrics like MATH and HumanEval, showcasing its versatility and ensuring its strength extends beyond image-text tasks. This balance of capabilities makes Pixtral a standout model in its class, pushing the boundaries of what multimodal systems can achieve.
Le Chat: The Practical Application
Le Chat, a free platform for users, has recently been upgraded with cutting-edge features powered by Pixtral Large, making it more versatile and user-friendly.
Advanced Canvas Interactions
Le Chat has introduced a dynamic canvas that allows users to interact more intuitively with visuals and annotations. This feature enhances collaborative workflows, offering greater precision and flexibility in creative projects. For instance, graphic designers can sketch, annotate, or brainstorm ideas in real-time during virtual meetings.
Web Search with Citations
Le Chat now includes an integrated web search feature that provides results along with accurate citations. This addition is ideal for research or fact-checking, as it offers transparency and reliability in the information retrieved. It is a game-changer for researchers, journalists, and students. It allows users to gather information from the web while automatically including proper citations, saving time and ensuring credibility in academic papers, articles, or reports.
Sophisticated Image Recognition and Generation
Le Chat leverages Pixtral Large’s advanced capabilities to analyze images in conjunction with textual context, enabling it to identify objects, scenes, and actions within photos with heightened precision. It might benefit industries like e-commerce. For instance, businesses can analyze product images to categorize inventory.
Moreover, through its collaboration with Black Forest Labs, an innovative image generation startup, Le Chat now incorporates Flux Pro for generating high-quality visuals (Learn more about the FLUX series). This integration allows users to create detailed images directly within the chat interface, catering to creative and professional needs.
Rapid and Accurate Document Comprehension
For users who work with extensive documents, Le Chat’s document comprehension tool, powered by Pixtral Large, ensures fast and precise analysis. This feature simplifies tasks such as summarizing, extracting data, or understanding key points in lengthy materials. It is perfect for professionals handling large volumes of text. For example, lawyers can quickly extract relevant clauses from lengthy contracts, while project managers can summarize technical reports for efficient decision-making.
Challenges and Future Trajectory
While Pixtral Large showcases impressive capabilities, Mistral AI still lacks some advanced voice and audio features found in rival products like OpenAI's ChatGPT Advanced Voice Mode. Meanwhile, feedback from early users has highlighted both the strengths and areas for improvement in Pixtral Large. Users have commended the model's high accuracy in image recognition tasks, but have also expressed a desire for enhancements in processing speed and overall efficiency.
These insights underscore Mistral's commitment to continuously refining and expanding Pixtral Large's functionalities to better meet the evolving needs of its user base. As the company looks ahead, addressing these areas of improvement will be crucial in solidifying Pixtral Large's position as a leading multimodal AI solution.
Conclusion
Pixtral Large is a representatitive for a significant breakthrough in the realm of multimodal AI, showcasing Mistral AI's technological prowess and commitment to pushing the boundaries of visual and textual understanding. The model's advanced architecture, led by the innovative PixtralViT vision encoder, greatly enables it to excel across a diverse range of benchmarks while maintaining strong performance on text-dealing tasks.
The implementation of Pixtral Large through Mistral's Le Chat platform further underscores the model's practical applications, empowering users with cutting-edge features like canvas, web search, image recognition and generation, and document understanding. As Mistral AI continues to refine and expand Pixtral Large's capabilities, the company well be furtherly well-positioned to solidify its position as a leader in the rapidly evolving multimodal AI landscape.
Try and Test here
- Le Chat: Mistral's versatile chatbot platform.
- Hugging Face Access: Pixtral-Large-Instruct-2411 is available for download with open weights, enabling users to self-host the model or fine-tune it for specific needs.
- API Integration: The API allows seamless incorporation of the Pixtral Large into various applications.