Unlocking the Future of Video Technology: Introducing Hunyuan Video by Tencent
By Horay AI Team|
Introduction
In the ever-evolving landscape of digital technology, video content has emerged as a cornerstone of communication, entertainment, and education. Recognizing the vast potential and the need for innovation in this space, Tencent, a global leader in technology and digital solutions, proudly presents Hunyuan Video. This cutting-edge open-sourced platform is designed to revolutionize the way we create, interact with, and disseminate video content. In this blog, we will delve into the features, benefits, and the transformative impact of Hunyuan Video.
Key Features of Hunyuan Video
1. AI-Powered Video Editing
- Intelligent Editing Tools: Hunyuan Video leverages advanced AI algorithms to provide smart suggestions for editing video content. These tools can analyze video footage to recommend optimal cut points, ensuring that the final product is smooth and engaging.
- Suggested Transitions: The AI can suggest visually appealing transitions between scenes, enhancing the overall flow and aesthetic of the video. This includes fade-ins, fade-outs, dissolves, and other effects that can make the video more dynamic.
2. Cloud Rendering & Deployment
- Rapid Rendering: Hunyuan Video uses cloud-based rendering technology to process and finalize video content quickly. This eliminates the need for powerful local hardware and allows for faster turnaround times.
- Deployment Across Platforms: The tool supports seamless deployment of videos across multiple platforms, including social media, streaming services, and websites. This ensures that your content is easily accessible to your audience regardless of where they choose to watch it.
3. Real-Time Interactive Streaming
- Low-Latency Streaming: Hunyuan Video offers real-time streaming with minimal latency, ensuring that live events are smooth and uninterrupted. This is crucial for maintaining engagement and interaction with the audience.
- Versatile Use Cases: Real-time interactive streaming is ideal for a variety of applications, including virtual conferences, live concerts, educational sessions, and webinars. It provides a flexible and dynamic platform for content creators to connect with their audience in real-time.
Under the Hood: Unveiling the Architecture of Hunyuan Video
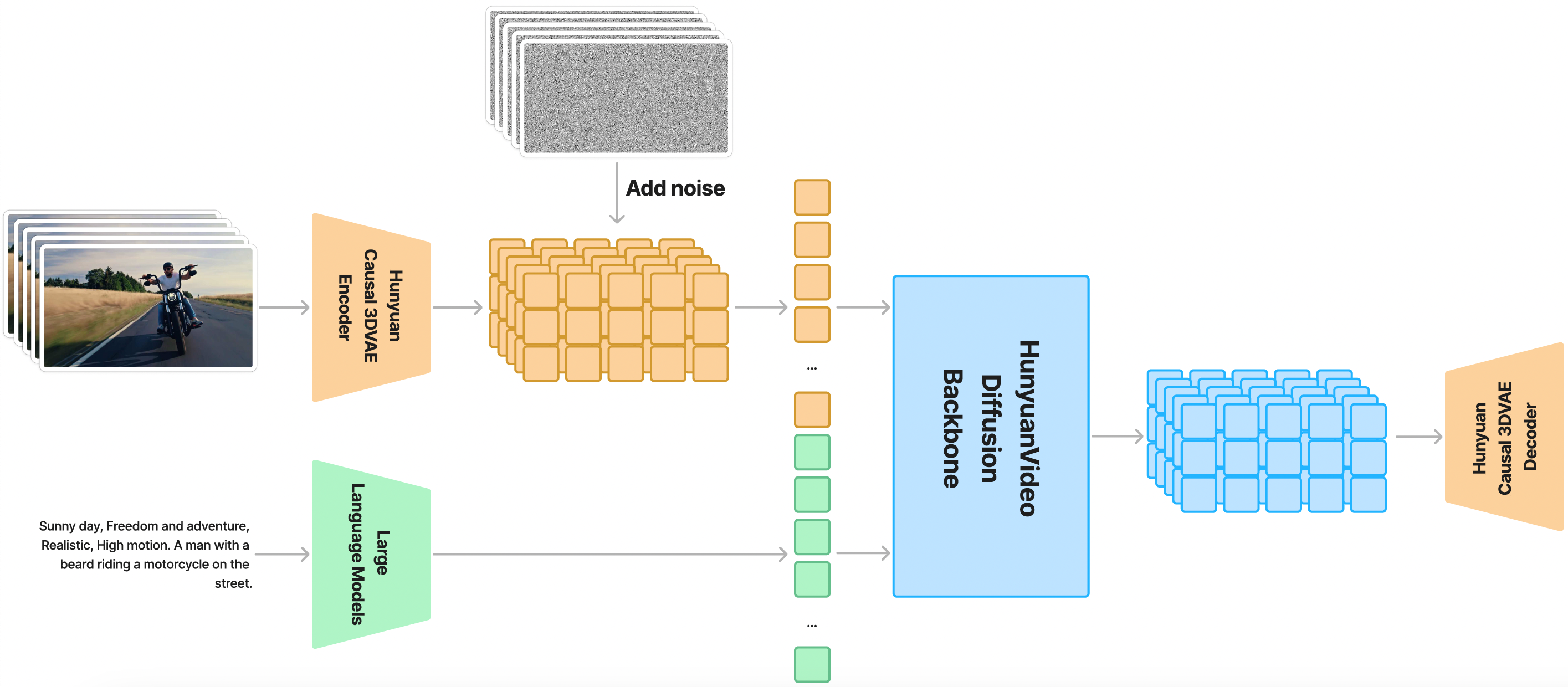
From this image, we can figure out that Hunyuan Video is trained on a spatial-temporally compressed latent space, achieved through a Causal 3D VAE. Text prompts are processed using a large language model and serve as the conditioning input. This example from the above image takes Gaussian noise and the conditioning input as inputs and generates an output latent. This latent output is then decoded into images or videos using the 3D VAE decoder.
1. Unified Image and Video Generative Architecture
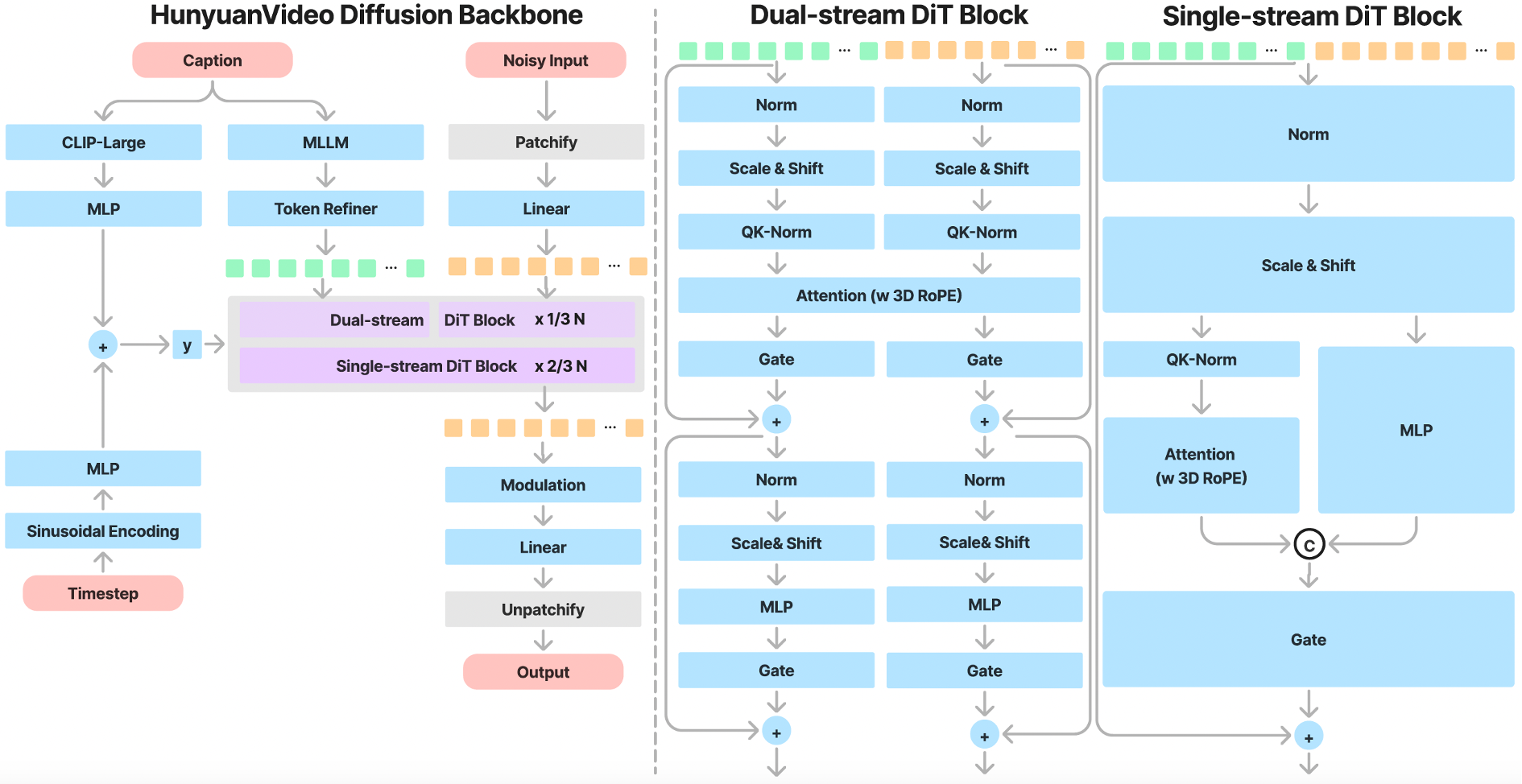
- Transformer Design with Full Attention Mechanism:Enables unified image and video generation.
- Dual-Stream to Single-Stream Hybrid Model:
- Dual-Stream Phase: Video and text tokens are processed independently through multiple Transformer blocks.
- Single-Stream Phase: Concatenated tokens undergo subsequent Transformer blocks for effective multimodal fusion, capturing complex interactions between visual and semantic information.
2. MLLM Text Encoder: Enhancing Multimodal Alignment
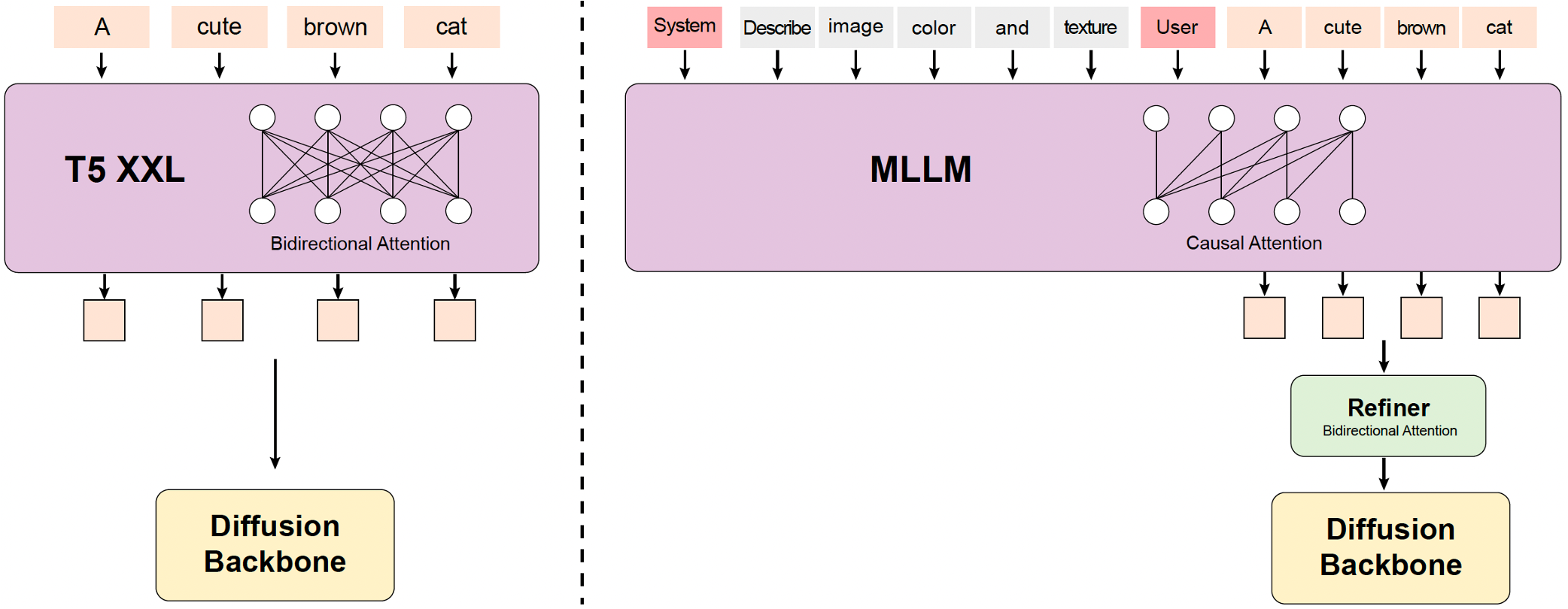
- Decoder-Only Structure: Offers better image-text alignment and superior image detail description compared to traditional encoders (e.g., CLIP, T5-XXL).
- Zero-Shot Learning Capability: Follows system instructions prepended to user prompts, enhancing focus on key information.
- Bidirectional Token Refiner: Introduced to enhance text features for better guidance in diffusion models.
3. 3D VAE for Efficient Compression

- CausalConv3D: Trains a 3D VAE to compress videos and images into a compact latent space.
- Compression Ratios: Video length (4x), space (8x), and channel (16x),
Deep Dive: Unlocking the Power of the Hunyuan Model
The Youtuber first introduces that Hunyuan model boasts an impressive scale with 13 billion parameters, outperforming competitors like Runway Gen 3 and Luma 1.6 in generating high-resolution videos. This massive parameter count allows the model to produce stunningly detailed and realistic content, making it a standout choice for content creators. Also, text-to-video generation with Hunyuan's advanced multimodal features could create more immersive and detailed content. By combining text, images, and other data types, Hunyuan can produce videos that are not only visually stunning but also rich in context and detail, offering a new level of creativity and depth.
While the model requires significant video memory (45-60 GB), a detailed installation guide is provided by this Youtuber for compatible GPUs, ensuring that those with the necessary hardware can fully leverage its capabilities. This makes it easier for creators to set up and start using Hunyuan, even if they are not tech-savvy. Additionally, the ability to upload short clips and experiment with resolution opens up new avenues for creativity and video enhancement, allowing YouTubers to push the boundaries of their content. Additionally, the Hunyuan model showcases its versatility and potential through various demonstrations. From the vivid details of a nighttime driving scenario to the whimsical exploration of text prompts offered by the Youtuber, these examples highlight the model's ability to handle a wide range of content types and styles. This versatility makes it a valuable tool for any YouTuber looking to create high-quality, engaging videos that captivate their audience.
Benchmark Performance: Leading the Way in Text-to-Video Synthesis
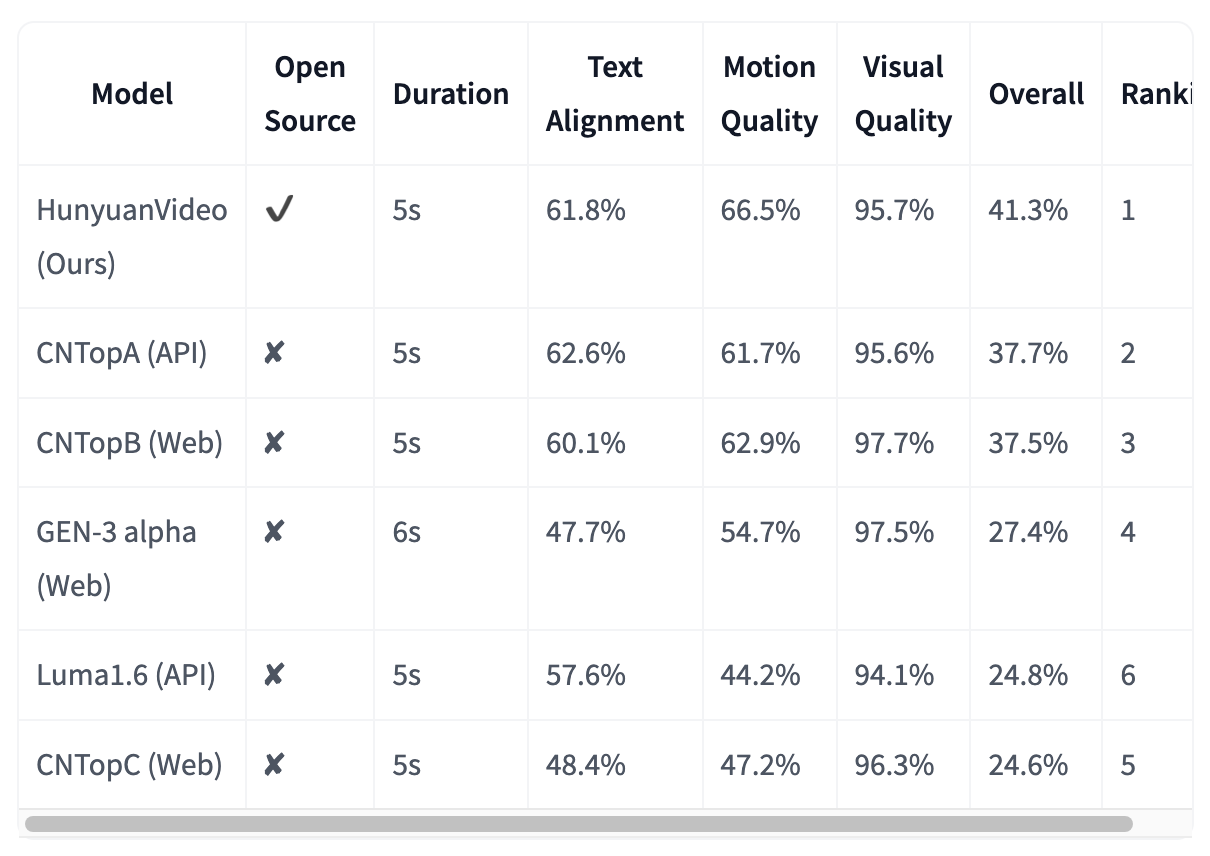
HunyuanVideo has been evaluated in this essay five other leading video generation models. The evaluation involved using 1,533 text prompts to generate videos with each model. These videos were then assessed based on three criteria: text alignment, motion quality, and visual quality. HunyuanVideo outperformed all other models, particularly excelling in motion quality. It demonstrated a significant advantage in generating videos with realistic and smooth motion. While all models showed strong performance in text alignment, HunyuanVideo also produced high-quality visuals.
Test here:
Huggingface: https://huggingface.co/tencent/HunyuanVideo#-open-source-plan
Hunyuan Video official website: https://hunyuanvideoai.com/dashboard
Conclusion
As we conclude our in-depth exploration of Hunyuan Video by Tencent, it's clear that this revolutionary platform is poised to redefine the boundaries of video technology. With its cutting-edge architecture, featuring a unified image and video generative model, Hunyuan Video is not just a tool, but a gateway to unprecedented creative possibilities. As we step into this new era of video technology, Hunyuan Video stands as a beacon of innovation, inviting creators, businesses, and enthusiasts to explore, experiment, and push the boundaries of what is possible. Whether you're looking to elevate your content, streamline your workflow, or simply experience the future of video today, Hunyuan Video is definitely your gateway!