Revolutionizing Art Creation: How Flux Model is Changing the Game
By Horay AI Team|
In the rapidly evolving landscape of artificial intelligence, Black Forest Labs has emerged as a frontrunner with its groundbreaking Flux text-to-image models. These models have not only captured the imagination of creators and developers worldwide but have also set new standards in the AI community.
This article delves into the success of the Flux models, specifically the three variants: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell]. We will explore the distinctive features, applications, and accessibility of each model, along with showcasing some stunning images generated by Flux and the prompts used to create them. Additionally, we will share insights from global market evaluations, highlighting the impact and reception of these models in the industry.
Join us as we uncover the transformative potential of Black Forest Labs' Flux models and how they are reshaping the future of AI-driven creativity.
Introduction to The Flux Family
Black Forest Labs is a distinguished team of AI researchers and engineers dedicated to pushing the boundaries of generative AI. The team is led by Robin Rombac, the first author of Stable Diffusion and the visionary behind SDXL and SD3. Robin, along with a group of talented researchers, left Stability AI to found Black Forest Labs, driven by a shared vision to innovate and advance the field of generative AI.
Driven by their dedication and commitment to developing and advancing state-of-the-art generative deep-learning models for media such as images and videos, the team at Black Forest Labs gave birth to the Flux family models.
Currently, to balance accessibility and model capabilities, FLUX.1 is available in three versions: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell]. Each variant is designed to cater to different user needs and use cases, ensuring that the benefits of advanced text-to-image synthesis are accessible to a wide range of users.
What's more, all three Flux.1 variants are built on a cutting-edge hybrid architecture that combines multi-modal and parallel diffusion transformers, scaled to 12 billion parameters. This architecture, further enhanced by flow matching and innovative techniques like rotary position embeddings and parallel attention layers, ensures that the models deliver unparalleled performance and efficiency.
As we delve deeper into this article, we will explore the unique features, applications, and real-world examples of each FLUX.1 variant. We will showcase the stunning images generated by these models and provide the prompts used to create them, giving you a firsthand look at the transformative potential of Flux. Additionally, we will share insights from global market evaluations, highlighting the impact and reception of these models in the industry.
Join us on this journey as we uncover the full potential of Black Forest Labs' Flux models and how they are reshaping the future of AI-driven creativity. Whether you are a professional designer, a developer, or simply a curious enthusiast, the Flux models have something to offer for everyone. Stay tuned to discover more.
Key Features of FLUX.1 Model
FLUX.1 [pro]
FLUX.1 [pro] offers state-of-the-art performance in image generation, featuring top-tier prompt adherence, visual quality, image detail, and output diversity. The Black Forest Labs is gradually increasing their inference compute for FLUX.1 [pro] in their API to ensure optimal performance and reliability.FLUX.1 [dev]
FLUX.1 [dev] is an open-weight, guided distillation model suitable for non-commercial applications. FLUX.1 [dev] is directly distilled from FLUX.1 [pro], offering similar quality and prompt adherence while being more efficient than standard models of the same size. The FLUX.1 [dev] weights are available on HuggingFace and can be tried directly on Fal.ai. For applications in commercial environments, a license from the company is required.FFLUX.1 [schnell]
The fastest model variant which is tailored for local development and personal use. FLUX.1 [schnell] is publicly available under the Apache 2.0 license. Similarly, the weights for FLUX.1 [dev] are available on Hugging Face, and the inference code can be found on GitHub and Hugging Face's Diffusers. FLUX.1 [schnell] is integrated with ComfyUI from day one.General Key Features
- Flexible Aspect Ratios and Resolutions: All FLUX.1 model variants support a wide and diverse range of aspect ratios and resolutions, catering to various use cases and requirements. This flexibility includes options at 0.1 megapixels for smaller, more detailed images and 2.0 megapixels for high-resolution, detailed outputs.
- Transformer-Powered Flow Models at Scale: All public FLUX.1 model's hybrid architecture combines multimodal and parallel diffusion transformer blocks, scaled to 12 billion parameters. The Black Forest Labs enhances the performance of these models by leveraging flow matching, a general and straightforward method for training generative models that encompasses diffusion as a special case. Furthermore, they boost model performance and hardware efficiency through the integration of rotary positional embeddings and parallel attention layers.
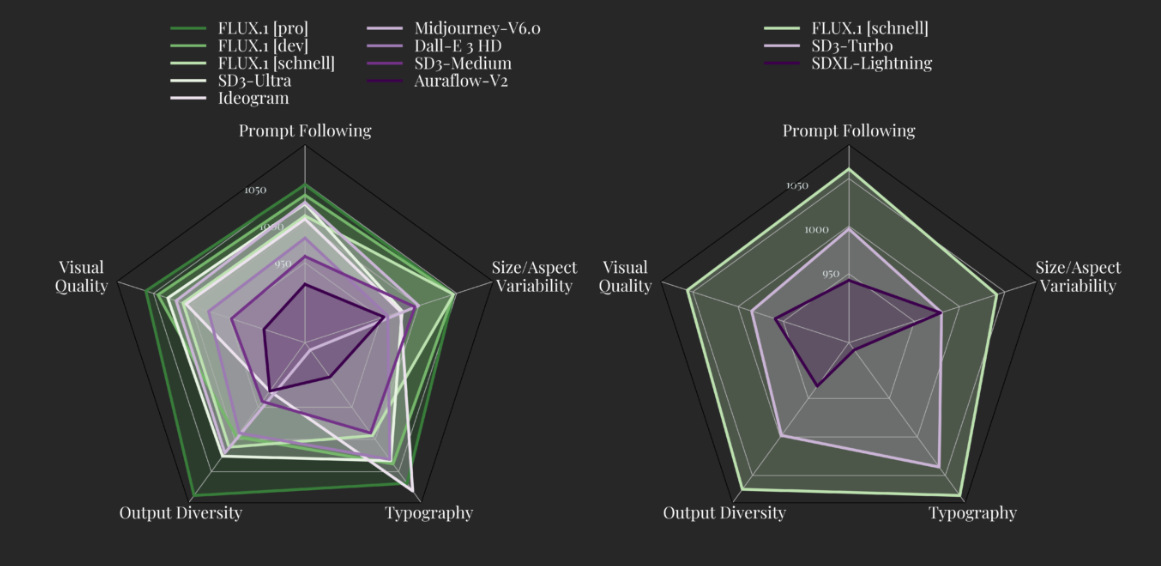
- A New Benchmark for Image Synthesis: FLUX.1 establishes a new state-of-the-art in image synthesis, setting new standards within its model class. Specifically, FLUX.1 [pro] and [dev] outperform popular models such as Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra in several key areas: visual quality, prompt adherence, size and aspect ratio variability, typography, and output diversity. Additionally, FLUX.1 [schnell] stands out as the most advanced few-step model, surpassing its in-class competitors and outperforming strong non-distilled models like Midjourney v6.0 and DALLE 3 (HD). The models are finely tuned to maintain the full range of output diversity from the pretraining phase, offering significantly improved capabilities compared to the current state-of-the-art, as demonstrated below.
Applications of FlUX.1 Model
- Digital Art and Graphic Design: FLUX.1 is a powerful tool that excels in generating high-quality, visually stunning images, making it ideal for digital art and graphic design projects. With its advanced ability to follow complex prompts and produce detailed, high-resolution images, the model stands out as an indispensable resource for artists and designers. Users can create unique and professional-grade visual content, significantly enhancing the quality and creativity of their work. Whether you're a professional artist, a graphic designer, or a creative enthusiast, FLUX.1 offers the tools you need to bring your visions to life with unparalleled precision and detail.
- Content Creation for Marketing and Advertising: This text-to-image model's precise prompt-following capabilities and diverse output options make it the perfect tool for creating marketing and advertising materials. The model can generate images that perfectly align with brand guidelines and campaign themes, ensuring consistency and brand integrity. Marketers and advertisers can produce engaging and consistent visual content quickly and efficiently, significantly improving the effectiveness of their campaigns. Whether it's social media posts, print ads, or digital banners, FLUX.1 helps ensure that every image resonates with the target audience and supports the overall marketing strategy.
- Perfect Size for Whatever Social Media and Online Platforms: As we mentioned before in the passage, it supports a wide range of aspect ratios and resolutions, making it ideal for creating content for various social media platforms and online channels. This flexibility ensures that images look great on different devices and formats. Content creators can produce visually appealing and platform-optimized images, enhancing engagement and reach on social media and other online platforms.
- Virtual and Augmented Reality (VR/AR): FLUX.1's capability to generate high-resolution and diverse images is particularly valuable for creating immersive VR and AR experiences. The model can produce detailed environments, characters, and objects, significantly enhancing the realism and interactivity of these applications. Developers and designers can create more engaging and realistic VR and AR content, improving user experience and expanding the potential of these technologies. Whether it's for gaming, education, or virtual tours, FLUX.1 provides the tools needed to bring these experiences to life with unparalleled detail and depth.
FLUX.1 Image Generation Display and Prompts
In this section, I will demonstrate FLUX.1's powerful image generation capabilities, highlighting its superior performance in image quality and prompt adherence, which surpasses existing models. FLUX.1 can generate high-quality images based on user-provided text prompts, whether they describe abstract concepts or specific scenes, with remarkable detail and realism. The model's multimodal architecture enables it to process and understand both text and image data simultaneously, capturing the complex relationships between them.
- Prompt1: a photo of a beautiful street in Freiburg with a tram passing by and people walking about and riding bikes

- Prompt2: beautiful anime artwork, a cute anime catgirl that looks depressed holding a piece of paper with a smile drawn on it over her mouth, she is about to cry

- Prompt3: two cute spiders in victorian outfits having a miniature tea party with a tiny table and teapot on a leaf, macro photo

- Prompt4: abstract chrome 80s scifi automaton, airbrush

- Prompt5: photograph of an elderly couple walking hand in hand on the beach

Evaluating FLUX.1 Across Various Providers
After the launch of the FLUX.1 model, many users from global markets shared their opinions after experiencing the series. Numerous evaluations were conducted to verify whether FLUX.1 truly lives up to the technical heights and stunning performance reported in official announcements. These users include ordinary consumers, influencers, and experts from academic and industrial sectors, who comprehensively assessed FLUX.1's performance through practical applications.
For example, in this video, @Matt Wolfe, a YouTuber with around 644,000 followers and a focus on AI, covered several topics related to the model. He provided overviews of the company's background, comparisons with competitors, and detailed assessments of FLUX.1's performance in image generation and prompt adherence. Matt also offered some prompt tricks to help users align their outputs with their imagination. Additionally, he discussed the future development of Black Forest Labs' text-to-video models. After watching the video, you will have a comprehensive perspective on the cutting-edge Flux.1 text-to-image model.
FAQ: FLUX.1 Text-to-Image Model
- Q: Who developed FLUX.1?A: FLUX.1 was developed by Black Forest Labs, a distinguished team of AI researchers and engineers led by Robin Rombac, the first author of Stable Diffusion and the visionary behind SDXL and SD3. Robin, along with a group of talented researchers, left Stability AI to found Black Forest Labs, driven by a shared vision to innovate and advance the field of generative AI.
- Q:How many variants does Flux.1 have and what are they?A:Three variants. They are FLUX.1 [pro], FLUX.1 [dev] and FLUX.1 [schnell].
- Q: What are the key features that distinguish FLUX.1 from other AI models?A: FLUX.1 stands out with its hybrid architecture that combines multimodal and parallel diffusion transformer blocks, scaled to 12 billion parameters. It offers flexible aspect ratios and resolutions, state-of-the-art performance in image generation, and advanced techniques like flow matching, rotary positional embeddings, and parallel attention layers. These features ensure unparalleled performance and efficiency.
- Q: On which platforms can FLUX.1 be accessed and tested?A: FLUX.1 [dev] and FLUX.1 [schnell] are available on Hugging Face, providing developers and enthusiasts with robust environments for integration and experimentation.
- Q: How does FLUX.1 perform in comparison to other models?A: FLUX.1 has consistently outperformed popular models like Midjourney v6.0, DALL·E 3 (HD), and SD3-Ultra in key areas such as visual quality, prompt adherence, size and aspect ratio variability, typography, and output diversity. FLUX.1 [schnell] is also the most advanced few-step model, surpassing its in-class competitors and strong non-distilled models like Midjourney v6.0 and DALL·E 3 (HD).